

The Abstraction and Reasoning Corpus (ARC) is a unique benchmark designed to measure AI skill acquisition and track progress toward achieving human-level AI.
The Abstraction and Reasoning Corpus (ARC) is a dataset created by François Chollet in 2019. It's designed to measure the gap between machine and human learning. The dataset consists of 1000 image-based reasoning tasks (Measure of Intelligence.)
ARC-AGI stands for “Abstraction and Reasoning Corpus for Artificial General Intelligence” and is aimed to measure the efficiency of AI skill acquisition on unknown tasks.
Now I know what you’re thinking, if AI can’t pass the test, this ARC thing must be pretty hard. Turns out, it isn’t. Most of its puzzles can be solved by a 5-year old.
The benchmark was explicitly designed to compare artificial intelligence with human intelligence. It doesn’t rely on acquired or cultural knowledge. Instead, the puzzles (for lack of a better word) require something that Chollet refers to as ‘core knowledge’. These are things that we as humans naturally understand about the world from a very young age.
Here are a few examples:
1. Objectness Objects persist and cannot appear or disappear without reason. Objects can interact or not depending on the circumstances.
2. Goal-directedness Objects can be animate or inanimate. Some objects are “agents” who have intentions and pursue goals.
3. Numbers & counting Objects can be counted or sorted by their shape, appearance, or movement using basic mathematics like addition, subtraction, and comparison.
4. Basic geometry & topology Objects can be shapes like rectangles, triangles, and circles which can be mirrored, rotated, translated, deformed, combined, repeated, etc. Differences in distances can be detected.
As children, we learn experimentally. We learn by interacting with the world, often through play, and that which we come to understand intuitively, we apply to novel situations.

With increasingly demanding consumers, developing a successful product requires more than just knowing about the product itself. You need to understand business, people, technology, design, and… a little bit of everything.

Explore the top free and paid AI tools for 2025, including the best AI chatbots, image and video generators, research assistants, and productivity apps. Compare features, pricing, and top picks for creative and professional use.

"Vibe Coding" is a form of programming where developers interact with code in a conceptual, AI-assisted manner, rather than manually writing each line.
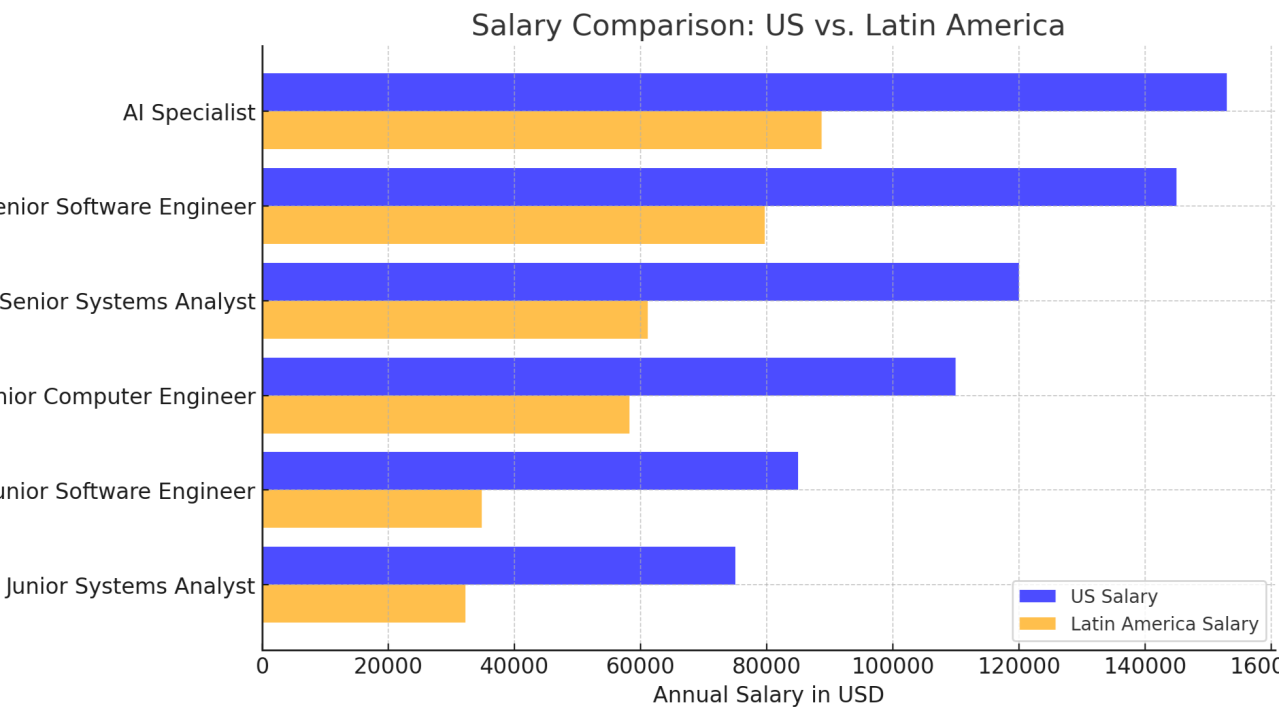
The shortage of technology professionals, including programmers, engineers, and analysts, has intensified in the United States due to the increasing demand for specialized skills and a limited supply of qualified talent.

The need arise from the need to streamline the analysis of exams performed on patients who may present detectable pathologies through imaging studies, assisting the physician in making a faster and more accurate diagnosis.
Researchers at Sakana.AI, a Tokyo-based company, have worked on developing a large language model (LLM) designed specifically for scientific research.