

There are some "sexy" words around the globe around Artificial Intelligence. That scenario results in a fusion of traditional data projects with new advantages.
Nowadays there is an unproductive time spent searching information in the organization (avg of 3.6 hours). Most of these search or data-related inquiries cross-functional collaboration, adding the potential risk of miscommunication, misalignment, and any other human creativity to delay answers... (I´ve suffered all of them). Most of the time the answer used to come from somebody with enough expertise in the domain area to guide the request, publish the answer, or help to polish the question.
Process at a Glance:
1) Document Processing: In this phase, documents must be gathered, embedded, and stored in the vector database. This process happens upfront before any client tries to search and will also consistently run in the background on document updates, deletions, and insertions. It's possible that this process will be done in batches from a data warehouse, with multiple iterations required to complete it. Also, it’s common to leverage streaming data structures to orchestrate the pipeline in real-time.
2) Serving: After a client enters a query along with some optional filters (e.g. year, category), the query text is converted into an embedding projected into the same vector space as the pre-processed documents. his enables the identification of the most pertinent documents from the whole collection. With the right vector database solution, these searches could be performed over hundreds of millions of documents in milliseconds.
AI search is based on vectors and algorithms to perform the search. Embeddings are designed to be information-dense representations of the dataset being studied. The most common format is a vector of floating. Here is an article that explains What are embeddings in Machine Learning
Last but not least data analytics is not just for somebody with technical skills, it requires also "domain experts".

With increasingly demanding consumers, developing a successful product requires more than just knowing about the product itself. You need to understand business, people, technology, design, and… a little bit of everything.

Explore the top free and paid AI tools for 2025, including the best AI chatbots, image and video generators, research assistants, and productivity apps. Compare features, pricing, and top picks for creative and professional use.

"Vibe Coding" is a form of programming where developers interact with code in a conceptual, AI-assisted manner, rather than manually writing each line.
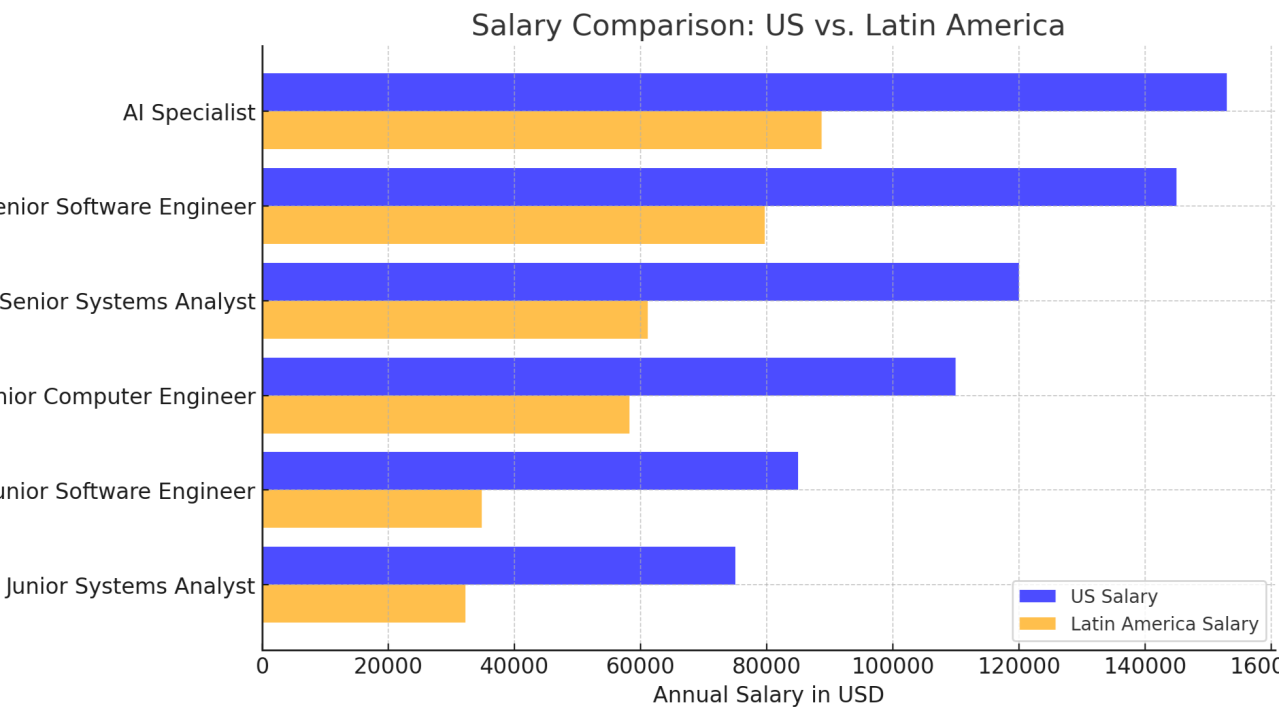
The shortage of technology professionals, including programmers, engineers, and analysts, has intensified in the United States due to the increasing demand for specialized skills and a limited supply of qualified talent.

The need arise from the need to streamline the analysis of exams performed on patients who may present detectable pathologies through imaging studies, assisting the physician in making a faster and more accurate diagnosis.
Researchers at Sakana.AI, a Tokyo-based company, have worked on developing a large language model (LLM) designed specifically for scientific research.